数据库的主键策略
生成数据库的ID有很多中方法,常见的有基于数据的自增ID,PostgreSQL,Oracle 可以有sequence,MySQL可以使用auto_increment。在系统并发量不大的情况下,这些都是可行的办法。但是如果并发量比较大,数据库很快会成为整个系统的瓶颈。
另外,有时候我们希望主键只是渐进递增,并不是逐个递增,比如订单表。
关于主键数据类型的选择
字符串和UUID不适合用作主键。
字符串和UUID的缺点是占用空进大,索引效率低。正常情况下使用Long只有8个字节,如果数据库不支持UUID的存储方式则要中用32字节,这是一笔不小的开销。
同时,UUID不可描述,除了作为唯一标识,没有任何意义,类似于:02500d31-7900-448c-b88d-5bacb11dfce3,看不出表达什么。
UUID的一个优点就是比较容易水平拆分,因为这些键全部是业务无关的。
所以,应该优先选择整型作为数据库的主键。
但是,在选择整型作为主键之前,应该先估算数据的规模,根据数据的规模确定整型的长度。
在PostgreSQL数据库中,每钟类型的属性如下:
| 类型 | 长度 | 表示范围 |
|---|---|---|
| smallint | 2 bytes | -32768 to +32767 |
| integer | 4 bytes | -2147483648 to +2147483647 |
| bigint | 8 bytes | -9223372036854775808 to +9223372036854775807 |
如果要存储世界的人口,那么使用integer类型是不合适的,此时可以考虑使用bigint。
就算每秒写入1000W条数据,Long类型也可以支持接近30000年,这已经够用了。
Long类型在性能和存储之间取得了平衡,往往是分布式系统首选的主键类型。
主键的生成策略
主键的生成策略有多种,目前没有一种绝对完美的方案,需要根绝业务的类型来选择。
1. 使用数据库自增ID
数据库递增的ID只能做到单表递增,做不到全局唯一。对于一些小型的应用来讲,这不会有什么问题。
数据库自增ID的缺陷是,无法在写入数据之前获得数据的ID,必须要在提交数据库之后才会返回ID。还有就是ID的产生依赖于数据库,可能会降低数据库的性能。并且,不可以后续分库分表。
2. 使用集中的ID生成策略
也就是专门提供一个服务用于批量生成ID。可以使用Redis的INCR,或者使用Zookeeper或者关系数据库也可以。这种方式最大的缺陷是又引入一个外部系统,依赖外部系统又带来新的不稳定性,并且实现起来也比较复杂。
3. 使用Twitter开源的Snowflake算法
使用Long类型,可以考虑使用Snowflake算法。
Snowflake是一种:时间戳+机器标识+自增序列的方式实现全局唯一ID。这种算法的好处是没有引入外部服务,没有网络调用的开销,安全高效。
这种方式生成的ID是渐进有序,并不是逐个递增。
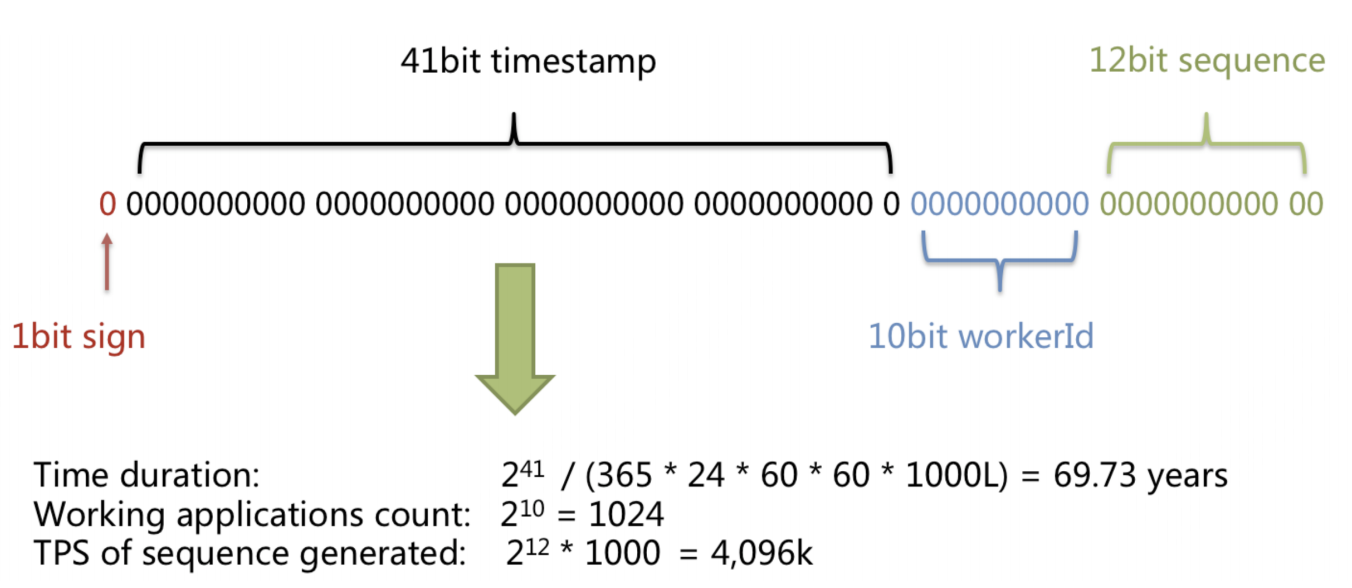
第一位是符号位,不使用。
这里的时间戳是毫秒级别的,所以换算成秒需要乘以1000。
余下63位:前面41为作为时间戳,可以表示大概不到70年的时间;余下10位可以作为机器标识,可以表示1024台机器;剩下12位是自增序列,理论上单台机器在1ms内可以产生4096个ID。
但是,需要注意的是,如果前端应用是JavaScript的话,是有可能面临丢失精度的问题,因为在JavaScript中,Number基本类型可以精确表示的最大整数是 2^53,如果用Number来存储Snowflake生成的ID肯定是不行的(虽然JavaScript引入来BigInt,但是目前来看还不成熟)。
针对这种情况,目前有两种解决方案:
- 后端应用在序列化的时候,把整型转化成字符串,这种方式简单直接,直接配置一下代码即可;
-
修改一下Snowflake算法,使用更小的时间戳:使用32位的秒级时间戳+5位的机器标识+16位自增。这样可以容纳32台机器,每秒可以生成6.5W个序列号。对于一个中型互联网公司足够用了。
Snowflake算法需要注意的问题:
需要注意CPU时钟回拨的问题, 这个主要是由于闰秒的原因。
如果按照原子钟来算,每一秒的绝对时间都是相等的,我们可以把这个叫作原子时间。但是地球的每一天自传的长度并不是相等的,大概平均每日会增加1.7ms。所以为了是原子钟的时间和地球自转的时间对齐,就有了闰秒的概念。
为什么会产生闰秒:是因为每一个太阳日的时间不是相等的,这就造成每一天每一秒的长度是不等的。但是我们计时的原子钟的时间每一秒都是相等的。如果没有闰秒来调节时间,这两个时间的差距会越来越大。
这种情况下给我们编程带来的问题就是调节时间是不确定的,我们没有办法规避。
避免这种情况的一个办法就是,如果一个业务不是时间特别敏感,我们最好关闭时钟同步。
4. 其它基于Snowflake的衍生算法
百度(uid-generator)
和Snowflake不同的是,调整了一下各个部位的长度。
workId,占用了22个bit位,时间占用了28个bit位,序列化占用了13个bit位。
同时,时间单位变成了秒,而不是毫秒。
美团(Leaf)& 滴滴的(Tinyid)
这两种,都是在Snowflake的基础上,添加了数据库或者zookeeper依赖,来管理ID的分配,比较适合他们自己的业务特点。
根据业务的类型,确定适当的主键策略
在一些访问并发量和数据量并不是特别大的表上,使用数据库递增的策略也是可取的。甚至说没有必要使用Long作为主键的类型。
我个人认为,Snowflake算法设计的非常漂亮,其它的衍生算法都带来一定程度的复杂性。虽然也解决来他们业务上的问题,但是我感觉不够漂亮。
Snowflake算法的正确性是基于时间只能往前,不能后退的假设。这个假设在绝大多数时候都是成立的
【参考连接】
闰秒
分布式唯一ID生成器
分布式唯一 ID 解析
百度UidGenerator
万亿级调用系统:微信序列号生成器架构设计及演变
UUID or GUID as Primary Keys? Be Careful!
tinyid
Leaf——美团点评分布式ID生成系统
百度uid-generator源码解析
分布式唯一 ID 之 Snowflake 算法
- 2020.02.19 初稿
- 2020.07.26 修改 完成PPT